
1. Apache Spark Overview
Apache Spark is an open-source, distributed computing system designed for fast computation on large-scale data processing tasks. It provides an interface for programming entire clusters with implicit data parallelism and fault tolerance.
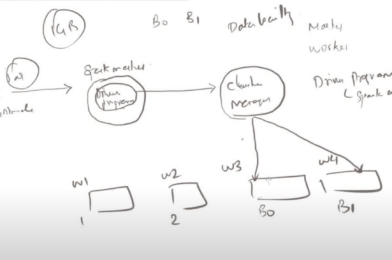
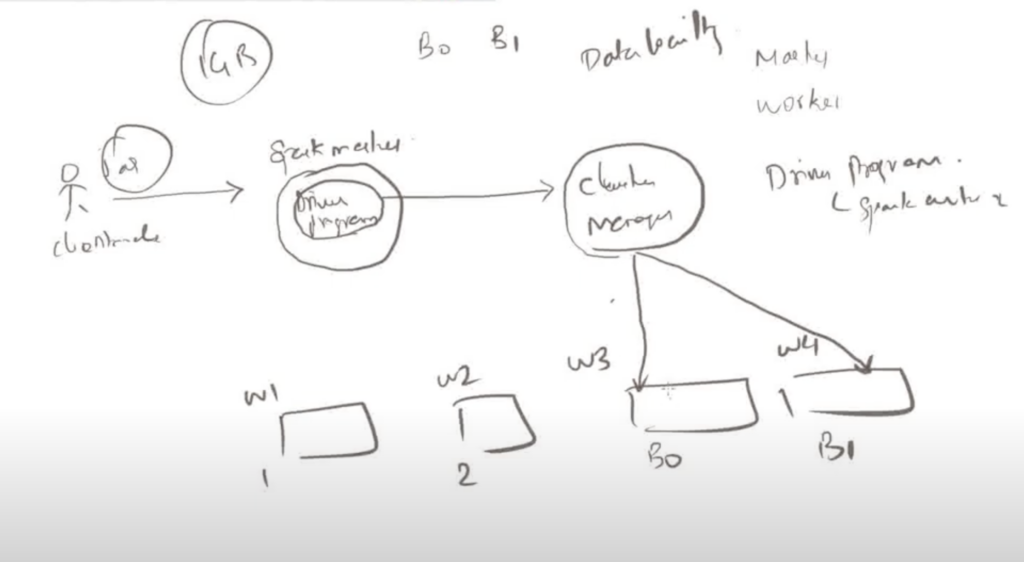
2. Spark Master
The Spark Master is the main node in a Spark cluster that manages the cluster’s resources and schedules tasks. It is responsible for allocating resources to different Spark applications and managing their execution. The Master keeps track of the state of the worker nodes and the applications running on them.
- Role: Manages resources in the cluster.
- Components Managed: Workers, applications.
3. Driver
The Driver program runs on a node in the cluster and is the entry point of the Spark application. It contains the application’s main function and is responsible for converting the user’s code into jobs and tasks that are executed by the Spark cluster.
- Role: Manages the execution of the Spark application.
- Responsibilities:
- Converts user code into tasks.
- Manages the job execution process.
- Collects and displays output.
4. Cluster Manager
The Cluster Manager is a system that manages the resources of the cluster. Spark can work with several different types of cluster managers, including:
- Standalone: Spark’s built-in cluster manager. It is simple to set up and is useful for smaller clusters.
- Apache YARN: Used for larger clusters in environments where Hadoop is deployed.
- Apache Mesos: A general-purpose cluster manager that can manage multiple types of distributed systems.
- Kubernetes: Used for running Spark on Kubernetes clusters, allowing containerized Spark applications to be managed at scale.
- Role: Allocates resources to Spark applications.
- Responsibilities:
- Manages the distribution of CPU, memory, and other resources.
- Works with the Spark Master to schedule tasks.
5. Spark Cluster Architecture
In a Spark cluster, the Driver communicates with the Cluster Manager to request resources (e.g., executors on worker nodes). The Cluster Manager allocates the resources and informs the Master node, which in turn assigns tasks to worker nodes.
- Driver: Runs the main Spark application.
- Master: Schedules resources across the cluster.
- Workers: Execute the tasks assigned by the Master.
- Cluster Manager: Manages the distribution of resources.
This architecture allows Spark to handle large-scale data processing efficiently by distributing the workload across multiple nodes in the cluster.
Spark Architecture
Apache Spark follows a master/slave architecture with two main daemons and a cluster manager –
- Master Daemon — (Master/Driver Process)
- Worker Daemon –(Slave Process)
- Cluster Manager

When you submit a PySpark job, the code execution is split between the Driver and the Worker Executors. Here’s how it works:
1. Driver
- The Driver is the main program that controls the entire Spark application.
- It is responsible for:
- Converting the user-defined transformations and actions into a logical plan.
- Breaking the logical plan into stages and tasks.
- Scheduling tasks to be executed on the Worker nodes.
- Collecting results from the workers if needed.
Driver Execution:
- Any code that doesn’t involve transformations on distributed data (e.g., creating RDDs/DataFrames, defining transformations, and actions like
collect,show,count) is executed in the Driver. - For example, commands like
df.show(),df.collect(), ordf.write.csv()are initially triggered in the Driver. The Driver then sends tasks to the Worker nodes to perform distributed computations.
2. Worker Executors
- Executors are the processes running on the Worker nodes. They are responsible for executing the tasks that the Driver schedules.
- Executors perform the actual data processing: reading data, performing transformations, and writing results.
Worker Execution:
- All operations that involve transformations (e.g.,
map,filter,reduceByKey) on distributed datasets (RDDs or DataFrames) are executed on the Worker Executors. - The Driver sends tasks to the Executors, which operate on the partitions of the data. Each Executor processes its partition of the data independently.
Example Workflow:
Let’s consider an example to clarify:
pythonCopy codefrom pyspark.sql import SparkSession
# Initialize Spark Session
spark = SparkSession.builder.appName("example").getOrCreate()
# DataFrame creation (executed by the Driver)
data = [("Alice", 34), ("Bob", 45), ("Catherine", 29)]
columns = ["Name", "Age"]
df = spark.createDataFrame(data, columns)
# Transformation (lazy, plan is created by the Driver but not executed)
df_filtered = df.filter(df["Age"] > 30)
# Action (Driver sends tasks to Executors to execute the filter and collect the results)
result = df_filtered.collect() # Executed by Executors
# The results are collected back to the Driver
print(result)
pyspark.sql import SparkSession
# Initialize Spark Session
spark = SparkSession.builder.appName("example").getOrCreate()
# DataFrame creation (executed by the Driver)
data = [("Alice", 34), ("Bob", 45), ("Catherine", 29)]
columns = ["Name", "Age"]
df = spark.createDataFrame(data, columns)
# Transformation (lazy, plan is created by the Driver but not executed)
df_filtered = df.filter(df["Age"] > 30)
# Action (Driver sends tasks to Executors to execute the filter and collect the results)
result = df_filtered.collect() # Executed by Executors
# The results are collected back to the Driver
print(result)https://sunscrapers.com/blog/building-a-scalable-apache-spark-cluster-beginner-guide/
https://medium.com/@patilmailbox4/install-apache-spark-on-ubuntu-ffa151e12e30