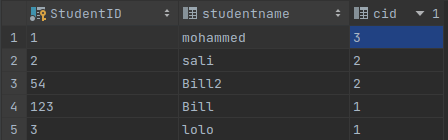
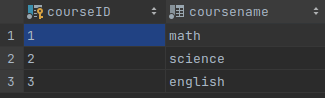
vocabularies
| Data Structure | Dimensions | Description |
|---|---|---|
| Series | 1 | 1D labeled homogeneous array, sizeimmutable. |
| Data Frames | 2 | General 2D labeled, size-mutable tabular structure with potentially heterogeneously typed columns. |
| Panel | 3 | General 3D labeled, size-mutable array. |
create data frame
data = {
"calories": [420, 380, 390],
"duration": [50, 40, 45]
}
#load data into a DataFrame object:
df = pd.DataFrame(data)
#change columns names
df=pd.DataFrame([[1,2,3],[4,5,6]],columns=['a','b','c'],index=['A','B'])
df.columns = ['x','y','z']
#index rows instead of numbers
df = pd.DataFrame(data, index = ["day1", "day2", "day3"])
#read csv
df = pd.read_csv('data.csv')
#read json
df = pd.read_json('data.json')
#series
a = [1, 7, 2]
myvar = pd.Series(a, index = ["x", "y", "z"])basic properties and functions
| 1 | axes Returns a list of the row axis labels |
| 2 | dtype Returns the dtype of the object. |
| 3 | empty Returns True if series is empty. |
| 4 | ndim Returns the number of dimensions of the underlying data, by definition 1. |
| 5 | size Returns the number of elements in the underlying data. |
| 6 | values Returns the Series as ndarray. |
| 7 | head() Returns the first n rows. |
| 8 | tail() Returns the last n rows. |
| 9 | columns:[] to edit or get columns |
read data frame
| 1 | .loc()Label based |
| 2 | .iloc()Integer based |
| 3 | .ix()Both Label and Integer based |
#by row index
df.loc[0]
print(df.loc[[0, 1]])
df =pd.DataFrame({'good':[1,2,3],'bad':[4,None,6]})
print(df.loc[1,"bad"])#nan object
print(df.iloc[0:2, 0:2])#all data frame
#ix
df = pd.DataFrame(np.random.randn(8, 4), columns = ['A', 'B', 'C', 'D'])
# Integer slicing
print df.ix[:4]
print df.ix[:,'A']
Iterators
#iterate by columns then inside Series(Values)
df=pd.DataFrame([[1,2,3],[4,5,6]],columns=['a','b','c'],index=['A','B'])
df.columns = ['x','y','z']
for col in df:
print(col)
print(df[col].dtypes)
for val in df[col]:
print(val)
#iterate by rows
for row_index,row in df.iterrows():
print row_index,row
#iterate by tuples
for index,*values in df.itertuples():
print(index)
print(values[0])
print(values[1])
print(values[2])sort
#index sort
import pandas as pd
import numpy as np
unsorted_df = pd.DataFrame(np.random.randn(10,2),index=[1,4,6,2,3,5,9,8,0,7],colu
mns = ['col2','col1'])
sorted_df=unsorted_df.sort_index()
print sorted_df
#values sort
import pandas as pd
import numpy as np
unsorted_df = pd.DataFrame({'col1':[2,1,1,1],'col2':[1,3,2,4]})
sorted_df = unsorted_df.sort_values(by=['col1','col2'])
print sorted_dfedit data frame
df=pd.DataFrame({'A': [1, 2, 3, 4, 5],"B":[1, 2, 3, 4, 5]})
df['B']=df['B'].apply(lambda x: math.pow(x,2))
df["B"]=[[math.sqrt(x),x/2] for x in df["B"]]merge
- left − A DataFrame object.
- right − Another DataFrame object.
- on − Columns (names) to join on. Must be found in both the left and right DataFrame objects.
- left_on − Columns from the left DataFrame to use as keys. Can either be column names or arrays with length equal to the length of the DataFrame.
- right_on − Columns from the right DataFrame to use as keys. Can either be column names or arrays with length equal to the length of the DataFrame.
- left_index − If True, use the index (row labels) from the left DataFrame as its join key(s). In case of a DataFrame with a MultiIndex (hierarchical), the number of levels must match the number of join keys from the right DataFrame.
- right_index − Same usage as left_index for the right DataFrame.
- how − One of ‘left’, ‘right’, ‘outer’, ‘inner’. Defaults to inner. Each method has been described below.
- sort − Sort the result DataFrame by the join keys in lexicographical order. Defaults to True, setting to False will improve the performance substantially in many cases.
import pandas as pd
left = pd.DataFrame({
'id':[1,2,3,4,5],
'Name': ['Alex', 'Amy', 'Allen', 'Alice', 'Ayoung'],
'subject_id':['sub1','sub2','sub4','sub6','sub5']})
right = pd.DataFrame(
{'id':[1,2,3,4,5],
'Name': ['Billy', 'Brian', 'Bran', 'Bryce', 'Betty'],
'subject_id':['sub2','sub4','sub3','sub6','sub5']})Concatenation
one = pd.DataFrame({
'Name': ['Alex', 'Amy', 'Allen', 'Alice', 'Ayoung'],
'subject_id':['sub1','sub2','sub4','sub6','sub5'],
'Marks_scored':[98,90,87,69,78]},
index=[1,2,3,4,5])
two = pd.DataFrame({
'Name': ['Billy', 'Brian', 'Bran', 'Bryce', 'Betty'],
'subject_id':['sub2','sub4','sub3','sub6','sub5'],
'Marks_scored':[89,80,79,97,88]},
index=[1,2,3,4,5])
print pd.concat([one,two],keys=['x','y'],ignore_index=True)cut continues values to classes
df = pd.DataFrame({'number': [1,2,3,4,5,6,7,8,9,10,11]})
df['bins'] = pd.cut(df['number'], (0, 5, 8, 11),
labels=['low', 'medium', 'high'])